
Two ways to solve ARC — and why I took the harder one
Published:
I spend most of my days thinking about a benchmark called ARC (the Abstraction and Reasoning Corpus). Each task gives you a handful of input→output grid pairs and asks you to produce the output for one new input. To a human it usually takes a few seconds. To most AI systems it’s a wall. That gap is the whole point — ARC is built to resist memorization and reward reasoning.
This post is less about ARC the benchmark and more about a choice I keep making, and re-justifying to myself.
Two ways
If you look at everything that works on ARC, the approaches split cleanly into two families.
Induction — program synthesis. You look at the demo pairs and search for a program that maps input to output, then run that program on the test input. The answer is an explicit, inspectable transformation. This is the world of brute-force DSL search, hand-written DSLs, library learning, and LLMs that write code.
Transduction — predict the output grid directly, no program in between. The dominant trick here is Test-Time Training: at inference, fine-tune a model on the demo pairs of this specific task and let it generalize. No explicit rule, just a model that has bent itself around the examples.
The striking finding from the 2024 ARC Prize is that these two families solve different sets of tasks. Induction-only tops out around the low 40s%; transduction-only, similar. Neither alone is SOTA. The state of the art ensembles both — precisely because they fail in different places.
So the pragmatic move is obvious: do both. And yet I’ve chosen to go all-in on one side — pure, symbolic induction. The slower one. The one that, on its own, has a known blind spot. Here’s the reasoning I keep coming back to.
A spectrum of recombination
There’s a nice way to see these two families as the opposite extremes of one axis: how you recombine pre-existing pieces.
- Program search recombines a small set of generic primitives deeply — short vocabulary, long compositions.
- Test-Time Training recombines a vast set of specialized building blocks (the functions baked into a network’s weights) shallowly — enormous vocabulary, a few gradient steps of glue.
Same underlying idea — “reuse and recombine” — but mirror images in the number of pieces, their generality, and the depth of composition. Once you see it that way, the question stops being “which one wins?” and becomes “where do you want intelligence to accumulate?”
Where the knowledge lives
That’s the question I actually care about. Across ARC systems, “the place where learning sticks” is different every time:
- In Test-Time Training, knowledge lives in model weights.
- In library-learning systems like DreamCoder, it lives in a growing DSL.
- In fixed-DSL search, it doesn’t accumulate at all.
My bet is a fourth option: let knowledge accumulate in a relational knowledge graph — a structured, symbolic semantic memory that grows as the system solves more problems. Not weights, not a flat library of program fragments, but relations between objects, grids, and tasks.
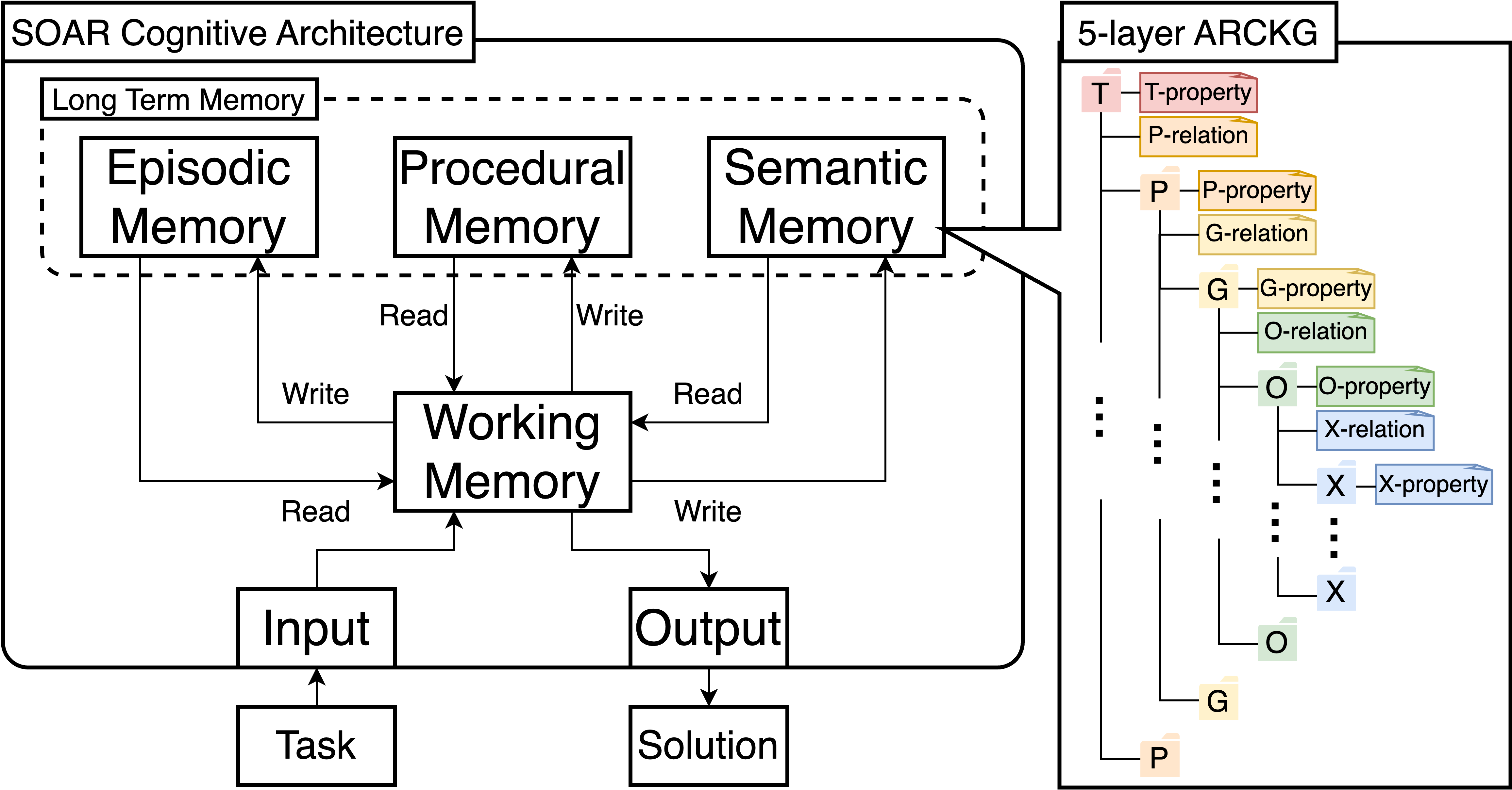 The system I’m building, ARBOR: a Soar-style working memory and decision cycle on the left, and on the right the knowledge it reads from and writes to — a 5-layer graph from Task down to Pixel. The “learning” lives in that graph, not in any weights.
The system I’m building, ARBOR: a Soar-style working memory and decision cycle on the left, and on the right the knowledge it reads from and writes to — a 5-layer graph from Task down to Pixel. The “learning” lives in that graph, not in any weights.
Why that, specifically?
- It’s auditable. Every step is formal logic you can read. When a symbolic system is wrong, you can point at the exact rule that was wrong. A weight matrix can’t tell you where a concept is stored.
- It’s bottom-up and self-extending. I want the system to grow its own abstractions from individual task pairs, not from a training corpus it had to see in advance.
- It borrows from how people actually reason. The architecture I work in leans on ideas from cognitive science — Soar’s decision cycle, structure-mapping as the basis for analogy. Generalization, in this view, is finding the shared skeleton between two cases — anti-unification — which has a real cognitive justification, not just a statistical one.
I gave this system a name: ARBOR — partly an acronym, partly Latin for tree, partly because it grows hierarchically, and partly (I’ll admit) because of my own handle, Albert-tree. The image of a tree that keeps branching is the whole vision in one word.
The honest part
None of this makes the blind spot go away. Pure symbolic induction structurally misses the tasks that transduction is good at — if SOTA is an ensemble and I’m building one branch, I am, by construction, leaving tasks on the table.
I think that’s a fair trade, for now, and here’s the bet behind it: the interesting open question isn’t “induction or transduction.” It’s whether you can take transduction’s strength — shallow recombination over a huge vocabulary — and express it symbolically. A very large semantic library, composed shallowly. If that works, you don’t bolt a neural module onto a symbolic one; you grow the symbolic side until it covers the same ground, while staying explainable the whole way.
I don’t know yet if that’s possible. That uncertainty is most of why this is interesting. But that’s the direction — and it’s why, when there were two ways to go, I took the harder one.
If you’re working on ARC, reasoning, or neuro-symbolic systems and any of this resonates (or you think I’m wrong), I’d genuinely like to hear it — my contact is in the sidebar.

